Rest of You - Digital Footprint
 - February 11, 2019
- February 11, 2019
This weeks assignment was to explore our online digital footprints. It could be anything from Google, Facebook, Twitter, packet sniffing, keylogging etc. Then analyze the information and find patterns in the data.
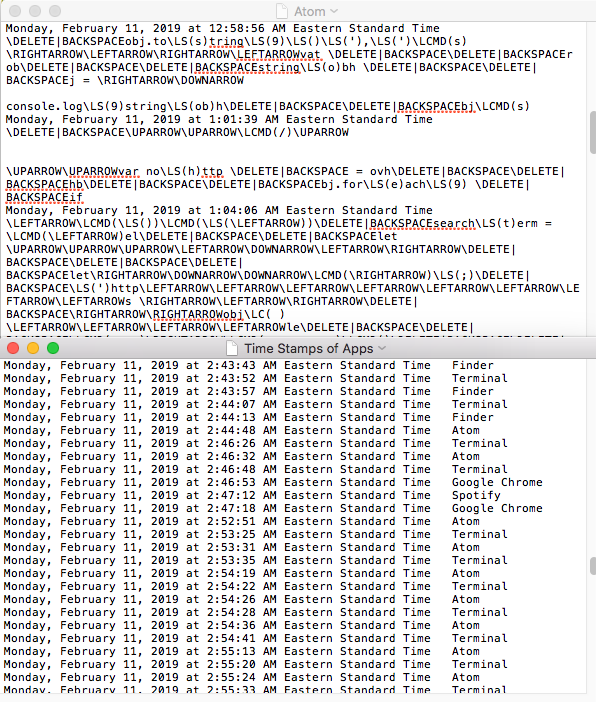
My initial idea was to install a keylogger. I could not get the logKext version to work. Instead, I found the macOS Swift-Keylogger and have that running on my computer right now. I have not had time to find a way to clean up that data yet - although it will be interesting to see what patterns I can find in that data.
The image below displays a brief printout from my efforts to complete this assignment last night.
I was curious to see what Google knows about me. For that reason I decided to use the GoogleTakeOut option to extract all the information Google has on me. As I figured, I provided me with a ton of information about search history, youtube, mail, location etc. dating back to >March 25th 2015< - I wonder what happened at this specific date - as this is the starting point of the data collection?
The data came in a form difficult to analyze. It came as a incredible long HTML string. In the browser it looked like this, having more than 40.000 searches all wrapped in several html tags.
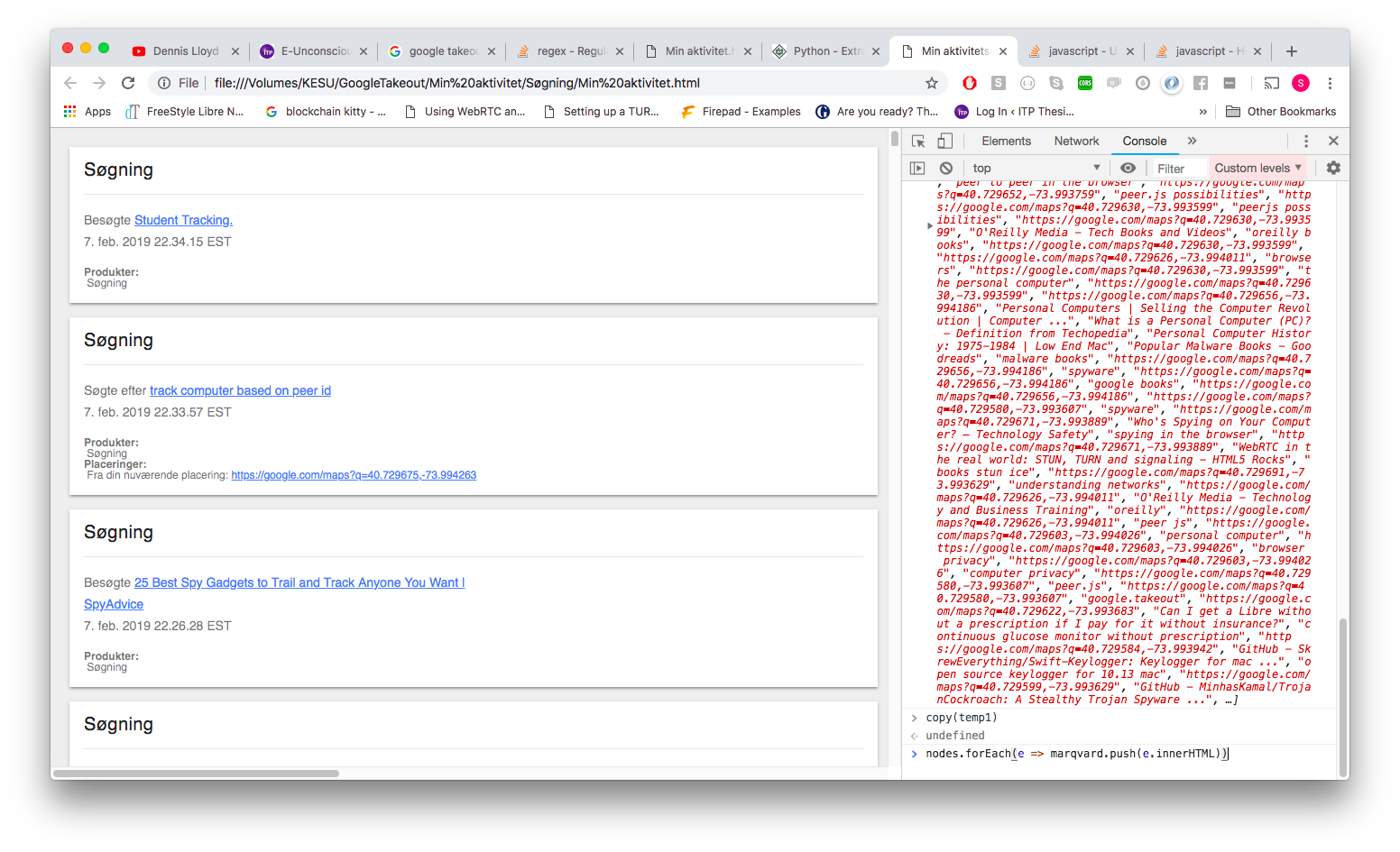
The information was showing pages I have visited or searched in the past 4 years.
I was interested in the links on the page to see what words and sentences I have been searching the most. These links corresponds to my inputs in the searchbar. To isolate that data, I used the console to get all “a-tags-innerHTML” and pass that into an array (length() = 44558!). I would then copy that array into a text file and use that in my node sketch.
When importing the node sketch I would filter out everything saying “http” or “https” because that would make my data harder to work with or give me an inaccurate count.
I would then make a counter to count the words/sentences (my search results) in the array. Finally, I would sort the counts, so that the most popular words would be displayed first.
The following is the result. However, when making conclusions it is important to keep in mind that it is a mix of pages I have visited and words/sentences I have searched for in the google chrome browser. Also, I think my code isolating the different words still needs a lot of adjusting to give an accurate picture. Still, however, it is interesting to look at the results.
Single words that are dominant.
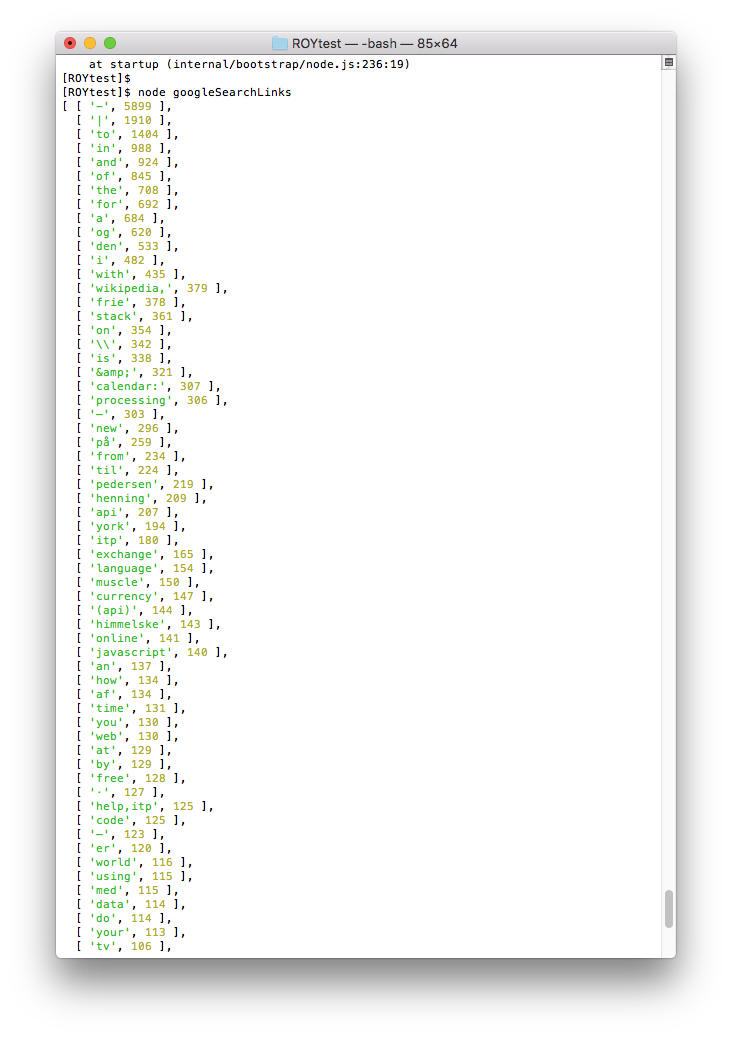
Although a lot of the words are neutral I still think it provides an interesting attempt to describe me. I see words relating to my favorite artist (“Henning” + “Pedersen” + “Himmelske”), what I study now (“itp” + “stack” + “processing” + “javascript” + “help.itp” ), what I used to study (“muscle”), my transition from Denmark to USA (“currency” + “exchange”).
Sentences/pages that are dominant.
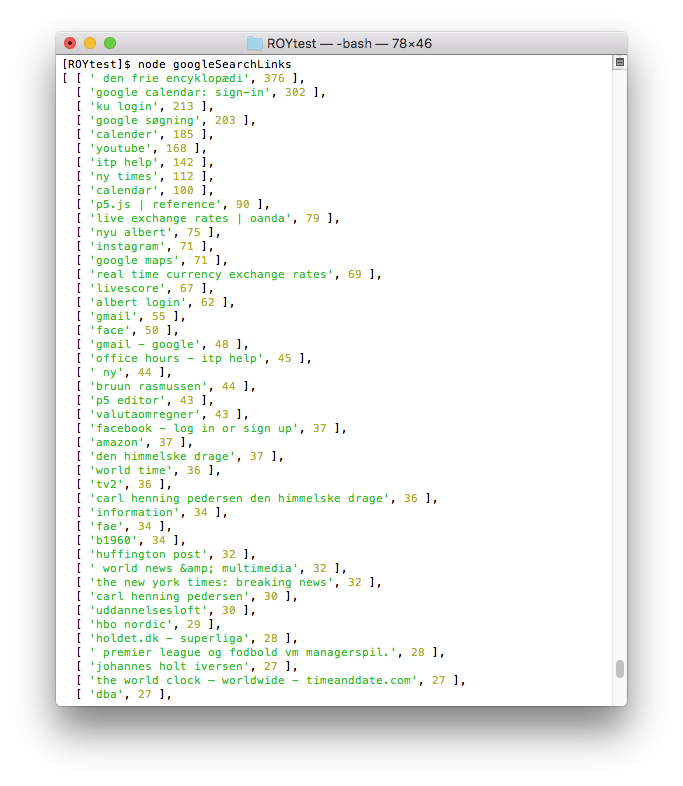
Similarly, when looking at sentences I have searched combined with pages I have visited an interesting list of information is provided. Login pages to googleCalendar, University of Copenhagen, NYU Albert and facebook are all there. So is wikipedia, live exchange rates, my old soccer club, the newspapers I read and watch. Altogether, this provides some interesting information I would like to explore further.